OpenStreetMap Data Wrangling using Python and SQL
Map Area
Albany, NY, United States
http://www.openstreetmap.org/export#map=11/42.7805/-73.8501
I chose this city, as I have been living in this area for last five years and would like an opportunity to contribute to its improvement in the openstreetmap.org project. I have chosen to explore the suburbs of Albany, NY rather than the downtown area.
Problems encountered in the map
After downloading the dataset and running it against a provisional data.py file, I noticed the following main problems with the dataset, as follows:
- Abbreviated and nonuniform street names ('St.', 'St', 'street', 'Ave', 'Ave.' etc).
- Incomplete street names (Sparrowbush, Deltour etc.).
- Inconsistent and incorrectly entered postal codes (12303-9998, 12180-8368 etc.).
- Incorrect city names (Schenectary, Rexrford etc.).
Abbreviated and incomplete street names
The osm file revealed basic street name inconsistencies caused due to abbreviations or use of small case letters. Some street names were incorrectly entered and were missing street type, for example Sparrowbush instead of Sparrowbush Road. An attempt was made in audit.py to fix these problems by replacing "St." with "Street", "road" with "Road", "rt" with "Route" etc.
A list of expected street types like Street, Avenue, Circle etc. was created which do not need to be cleaned. If the last word of a street type was not in the expected list, they were stored in a separate dictionary. It gave an idea about what inconsistent street types are present in the data. The osm file was scanned for tags that were street names (type="addr:street") and the old abbreviated street name was mapped to a new better one using a mapping dictionary. A snippet of the code to update street name is given below.
def update_name(name, mapping):
n = street_type_re.search(name) #get the street type
if n:
n = n.group()
for m in mapping: # check if a better name exists for a street type in mapping dict
if n == m:
name = name[:-len(n)] + mapping[m] #replace old name with new
return name
Incorrect postal codes
Most postal codes in the Capital District region are all five digits for this map, but some are 9 digits having trailing digits (12180-8368) after the first five digits. Wrote some code to drop the trailing digits and the '-' after the five digit postal code.
One particular postal code 1220y stood out as incorrectly entered. I needed to find out what address it belonged to in order to replace it with the correct code. It belonged to 1, State Street, Albany which has zip code 12207.
def update_postcode(postcode): #update postal code to remove trailing digits
if len(postcode)==10 and postcode[5] == '-':
return postcode[:5]
elif postcode == "1220y":# update the one instance of incorrectly entered postal code for this extract
return "12207"
else:
return postcode
Incorrect City Names
While most city names in this dataset were fine, some were incorrectly spelled. Like Schenectary instead of Schenectady.
def update_city(name, mapping_city):
for m in mapping_city: #replace incorrect name with correct one from mapping dict
if name == m:
name = mapping_city[m]
return name
Data Overview and Statistics
The data from the OSM XML file was converted to tabular form which could be written into CSV files. These CSV files could easily be imported to SQL tables.
File Sizes
import os
print('The albany.osm file is {} MB'.format(os.path.getsize('albany.osm')/1.0e6))
print('The osm.db file is {} MB'.format(os.path.getsize('osm.db')/1.0e6))
print('The nodes.csv file is {} MB'.format(os.path.getsize('nodes.csv')/1.0e6))
print('The nodes_tags.csv file is {} MB'.format(os.path.getsize('nodes_tags.csv')/1.0e6))
print('The ways.csv file is {} MB'.format(os.path.getsize('ways.csv')/1.0e6))
print('The ways_tags.csv is {} MB'.format(os.path.getsize('ways_tags.csv')/1.0e6))
print('The ways_nodes.csv is {} MB'.format(os.path.getsize('ways_nodes.csv')/1.0e6))
Number of nodes
sqlite> SELECT COUNT(*) FROM nodes;
397468
Number of ways
sqlite> SELECT COUNT(*) FROM ways;
46401
Number of unique contributing users
sqlite> SELECT COUNT(DISTINCT(e.uid))
...> FROM (SELECT uid FROM nodes UNION ALL SELECT uid FROM ways) e;
556
Top contributing users
SELECT e.user, COUNT(*) as num
FROM (SELECT user FROM nodes UNION ALL SELECT user FROM ways) e
GROUP BY e.user
ORDER BY num DESC
"nfgusedautoparts" "101654"
"woodpeck_fixbot" "97147"
"JessAk71" "50979"
"ke9tv" "35085"
"KindredCoda" "21036"
"RussNelson" "15605"
"Юкатан" "12697"
"eugenebata" "6639"
"bmcbride" "6056"
"EdSS" "5713"
Users whose posts appear only once
sqlite> SELECT COUNT(*)
...> FROM
...> (SELECT e.user, COUNT(*) as num
...> FROM (SELECT user FROM nodes UNION ALL SELECT user FROM ways) e
...> GROUP BY e.user
...> HAVING num=1) u;
116
Additional Data Exploration
Most Popular Cuisines
sqlite> SELECT tags.value, COUNT(*) as num
FROM (SELECT * FROM nodes_tags
UNION ALL
SELECT * FROM ways_tags) tags
WHERE tags.key = 'cuisine'
GROUP BY tags.value
ORDER BY num DESC LIMIT 10;
pizza,74
sandwich,63
burger,62
italian,39
chinese,33
mexican,23
coffee_shop,16
donut,16
diner,13
american,12
Most popular pizza places
Since pizza is one of the most popular food here, which are the places serving pizza?
SELECT tags.value, COUNT(*) as total_num
FROM (
SELECT * FROM nodes_tags
JOIN (SELECT DISTINCT(id) FROM nodes_tags WHERE value = "pizza") i ON nodes_tags.id = i.id
UNION ALL
SELECT * FROM ways_tags
JOIN (SELECT DISTINCT(id) FROM ways_tags WHERE value = "pizza") j ON ways_tags.id = j.id
) tags
WHERE tags.key = 'name'
GROUP BY tags.value
ORDER BY total_num DESC LIMIT 10;
"I Love NY Pizza",3
"Papa John's",3
"Pizza Hut",3
"Domino's Pizza",2
Dominos,2
"Paesan's Pizza",2
"A J's Pizzeria",1
"Bacchus Woodfired",1
"Big Guys Pizzeria",1
"Chef's Takeout Restaurant",1
Top Fast Food Chains
SELECT tags.value, COUNT(*) as total_num
FROM (SELECT * FROM nodes_tags
JOIN (SELECT DISTINCT(id) FROM
nodes_tags WHERE value = "fast_food") i ON nodes_tags.id = i.id
UNION ALL
SELECT * FROM ways_tags
JOIN (SELECT DISTINCT(id) FROM ways_tags WHERE value = "fast_food") j ON ways_tags.id = j.id
) tags
WHERE tags.key = 'name'
GROUP BY tags.value
ORDER BY total_num DESC LIMIT 10;
"Dunkin' Donuts",33
"McDonald's",27
Subway,24
"Burger King",13
"Subway Subs",10
"Wendy's",10
"Mr Subb",8
"Taco Bell",6
"Bruegger's Bagels",4
"Moe's Southwest Grill",4
Number of Stewart's' Shops
Stewart's is a very popular convenience store in this area. How many Stewart's stores are there in the map?
SELECT COUNT(*) FROM
(SELECT * FROM nodes_tags WHERE value LIKE "Stewart's"
UNION ALL
SELECT * FROM ways_tags WHERE value LIKE "Stewart's" );
121
How are they spread across the region? What cities have most shops?
SELECT tags.value, COUNT(*) as total_num
FROM (SELECT * FROM nodes_tags
JOIN (SELECT DISTINCT(id) FROM nodes_tags WHERE value LIKE "Stewart's") i ON nodes_tags.id = i.id
UNION ALL
SELECT * FROM ways_tags
JOIN (SELECT DISTINCT(id) FROM ways_tags WHERE value LIKE "Stewart's") j ON ways_tags.id = j.id
) tags
WHERE tags.key = 'city'
GROUP BY tags.value
ORDER BY total_num DESC
LIMIT 5;
Albany,13
Schenectady,11
Troy,9
Scotia,4
Altamont,3
Analysing timestamps
Since the timestamps for all data entries are available in both nodes and ways tags, I decided to take a look if the map has been kept up to date by volunteers or it needs more contribution? The following bar graph shows the frequency of entries by year.
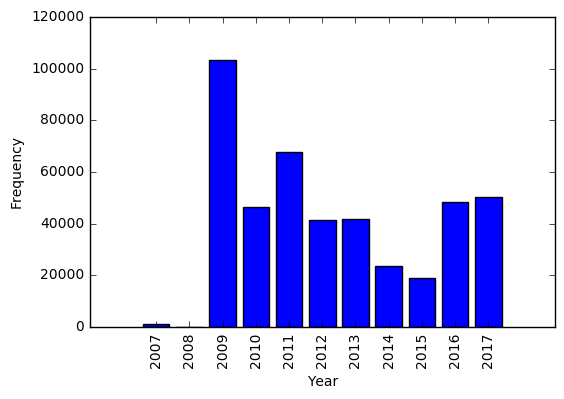
The figure shows that while 2009 has maximum entries, for the consecutive years the map has been consistently updated too, until recently in October 2017.
Conclusion
The data for Albany, NY area was cleaned and street names, postal codes and city data was validated for accuracy. Some basic statistics about the data were obtained and additional exploration about popular cuisines, pizza places, fast food chains etc. was done.
Additional Ideas for improving OSM
After this review, it's seen that the data for Albany area is incomplete, though I believe it's been well cleaned for this exercise. Some additional ideas that I came across which can be implemented:
- While looking at Stewart Shops in the area, I found that some shops were missing the city field. This also seems to be the case for other entries. Data entries should be validated for completeness.
- Subway and Subway Subs point to the same chain but are listed separately. This data can be cleaned up.
- Pizza Hut is listed as both pizza and fast food. This information should be standardized.
- The timestamps of entries can be further analysed to find out how recent the data is, and how frequently it is being contributed to. This could help contributors to find where there is most need of updating the data.
Benefits and anticipated problems
Standardizing the data on openstreetmap.org and validating it for correctness and completeness will make the data more useful and accessible to customers, increasing it's popularity too. It will bring it at par with other popular map services like Google or Bing Maps which in turn will help improve the data, as more people would contribute to the project.
But since OSM is run entirely by volunteers, doing this could be more challenging. For example, it may not be practical to physically verify latest location information. Or to obtain missing information.
Implementing some methods of cross validation might help. So would encouraging creation of better bots/scripts to import data to OSM.